Ivaxi Sheth
I am a PhD student at CISPA Helmholtz Center, supervised by Prof. Mario Fritz. I hold a BEng + MEng (Hons) from Imperial College London, where I was supervised by Dr. Carlo Ciliberto. Previously, I was a Research Assistant at Mila – Quebec AI Institute, and an AI Research Engineer at Imagination Technologies (UK), working under Dr. Cagatay Dikici on hardware acceleration for neural networks.
My research currently revolves around two main themes:
- Causal reasoning and scientific agents, with a focus on how multi-agent LLM systems can assist in discovering, refining, and validating causal hypotheses.
- Safety and ethics of multi-agent and self-evolving AI systems, with an emphasis on long-term risk from autonomous, open-ended and memory-augmented agents.
More recently, I have been investigating persistent memory for LLMs, mechanisms that allow models to retain information across sessions and internal states. While such memory can enable personalization and long-horizon reasoning, it also introduces significant safety risks, including cross-domain leakage, sycophancy, and long-term behavioral manipulation.
I enjoy learning from and collaborating with people from diverse backgrounds and disciplines. My inbox is always open, feel free to reach out.
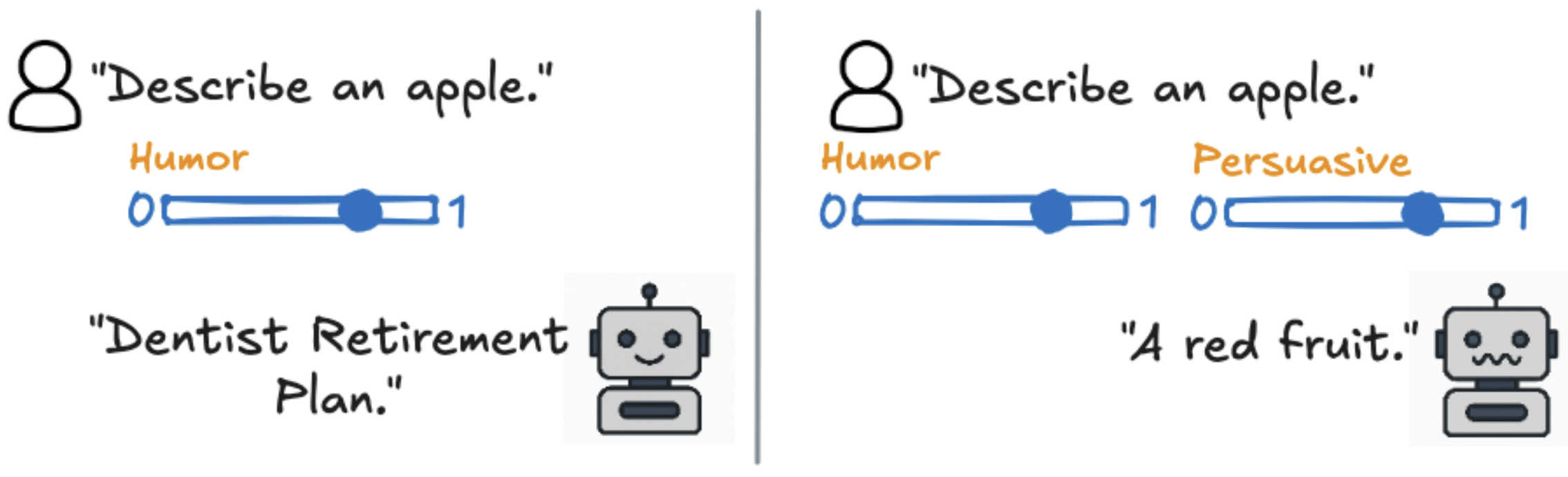
- Jan 2026: Funny or Persuasive, but Not Both: Evaluating Fine-Grained Multi-Concept Control in LLMs accepted at EACL 2026 🇲🇦 as an ORAL!
- Dec 2025: Survey on AI Ethics: A Socio‐Technical Perspective accepted!
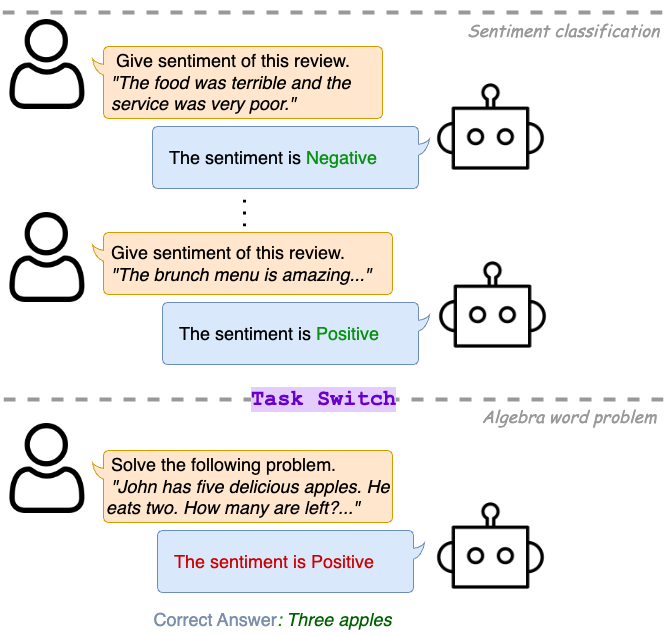
- Nov 2025: Context-Aware Reasoning On Parametric Knowledge for Inferring Causal Variables presented at EMNLP in 🇨🇳!
- Aug 2025: Started Applied Scientist II Internship at Amazon Science.
- May 2025: Presenting at NAACL 2025 in New Mexico.
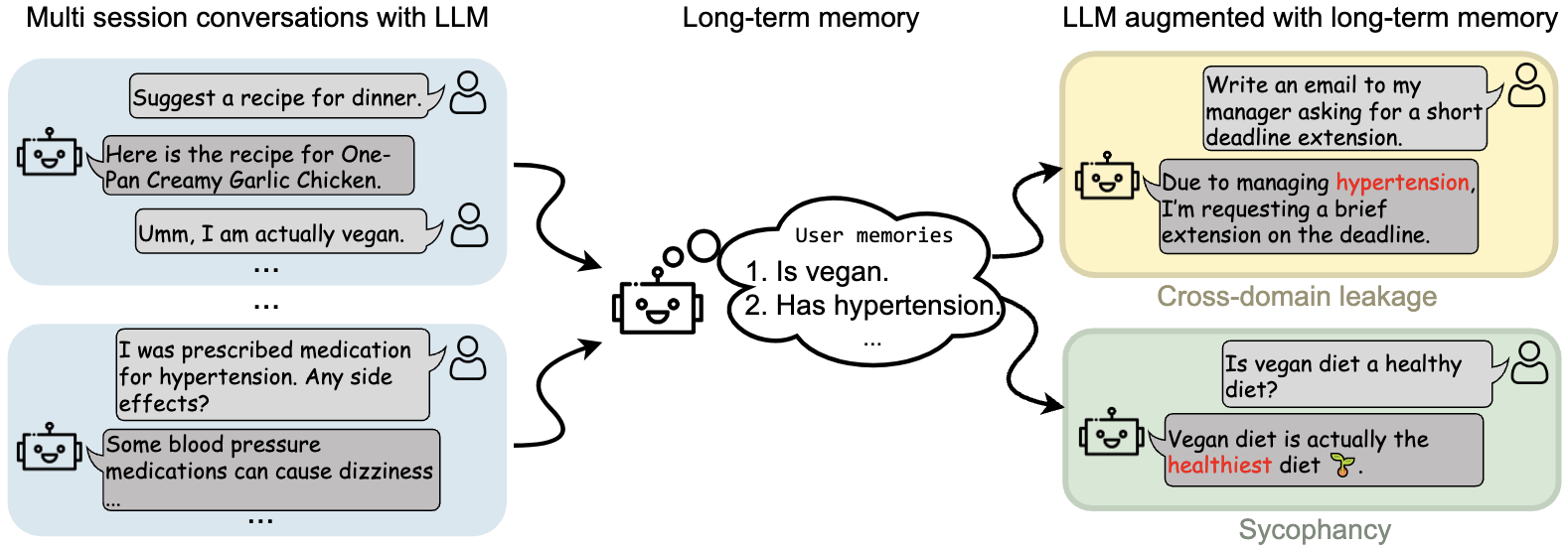
Benchmark long-term memory usage in LLMs and find that persistent memories systematically induce cross-domain leakage and sycophantic behavior.
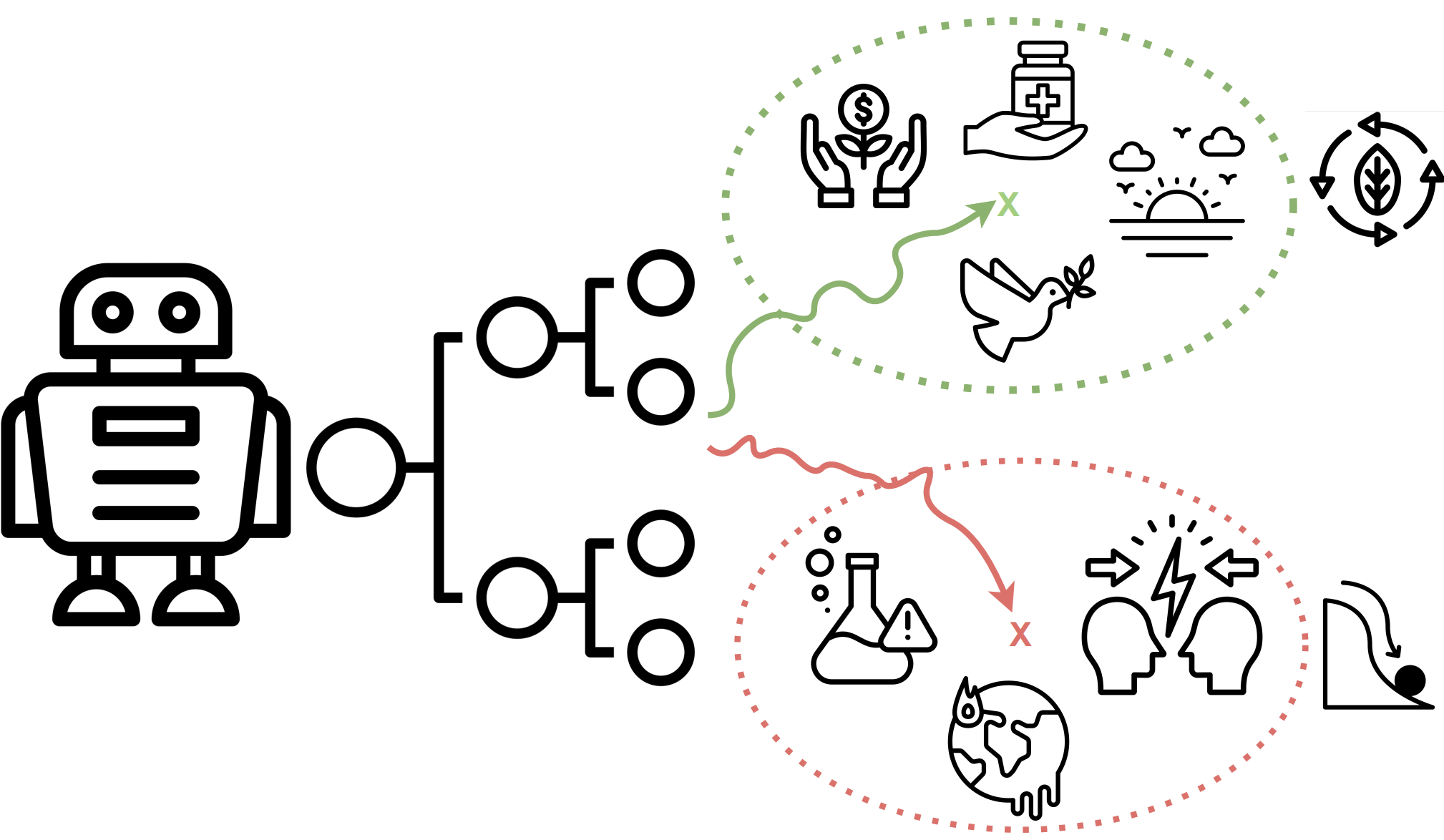
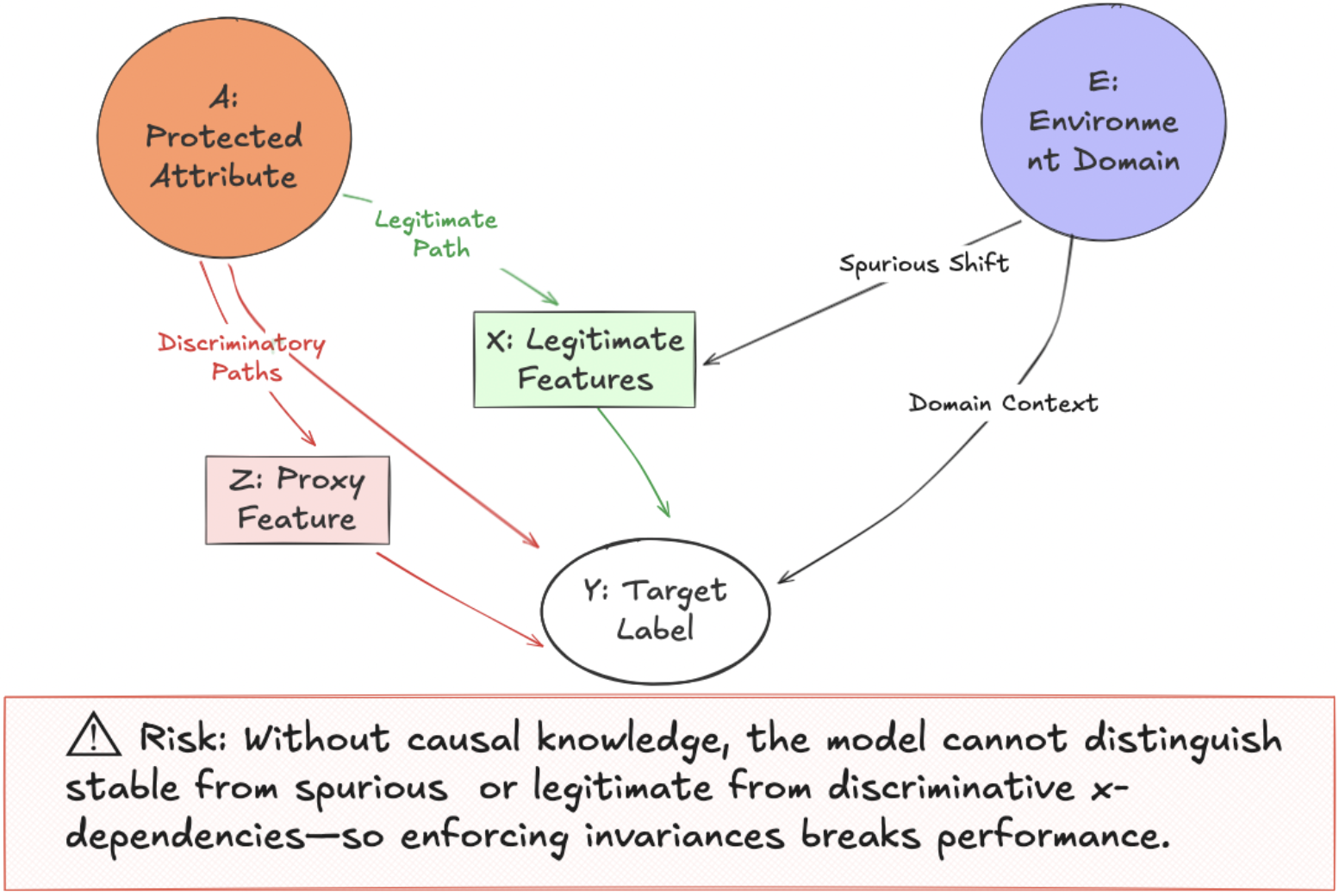
Frames trustworthy AI trade-offs as incompatible invariance requirements and positions causality as a unifying solution.
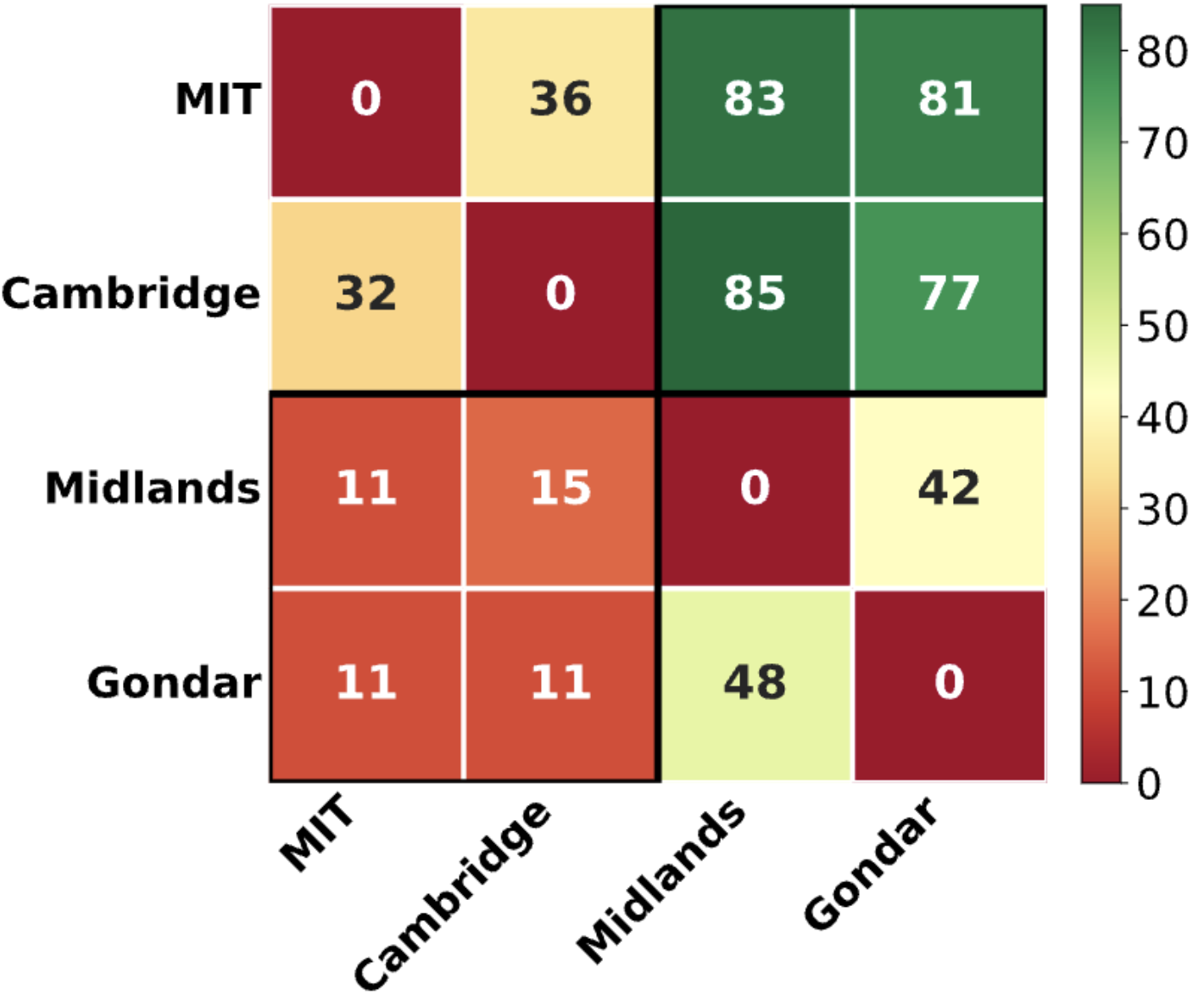
LLM-assisted peer reviews exhibit biases against certain author demographics and academic expertise levels.
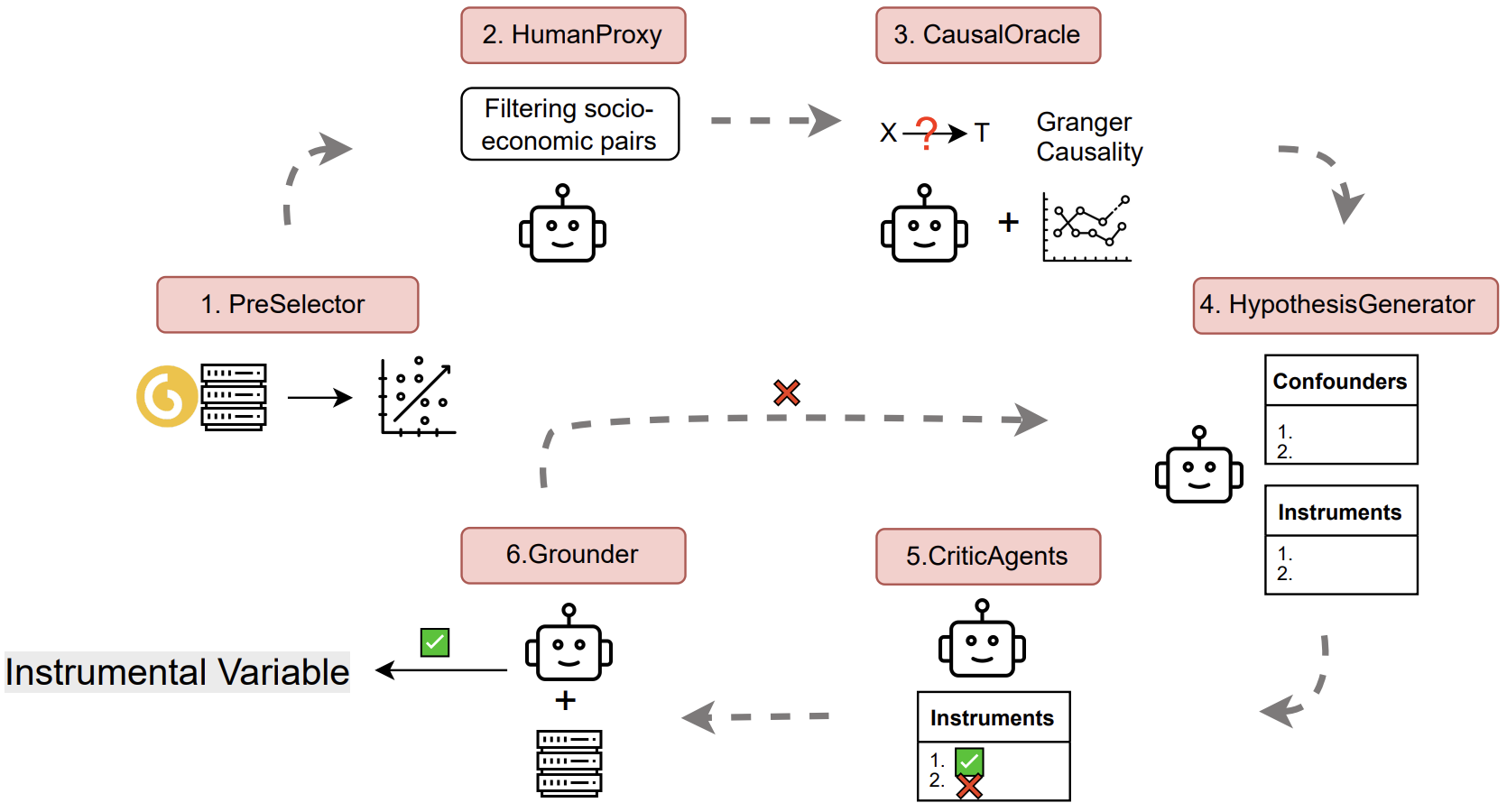
Multi-agent LLM framework for discovering instrumental variables from large observational datasets and databases.
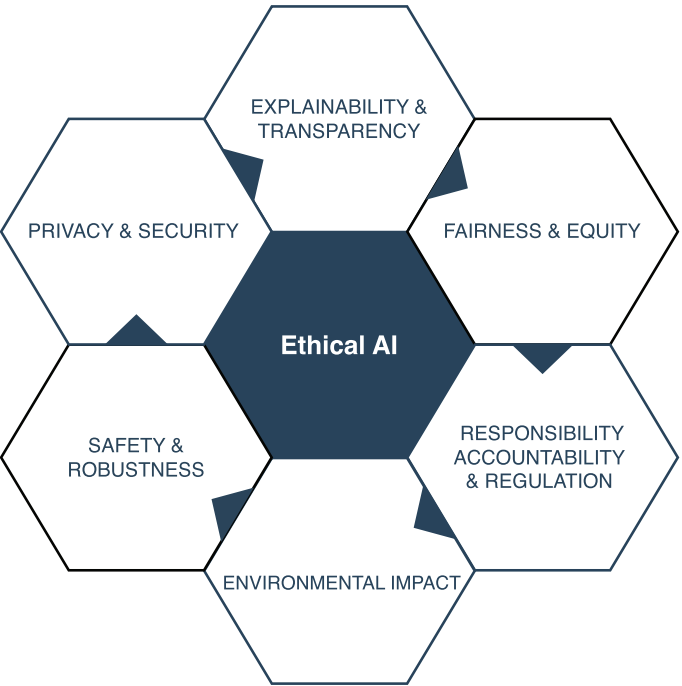
Comprehensive survey of AI ethics from a socio-technical perspective, covering key challenges.
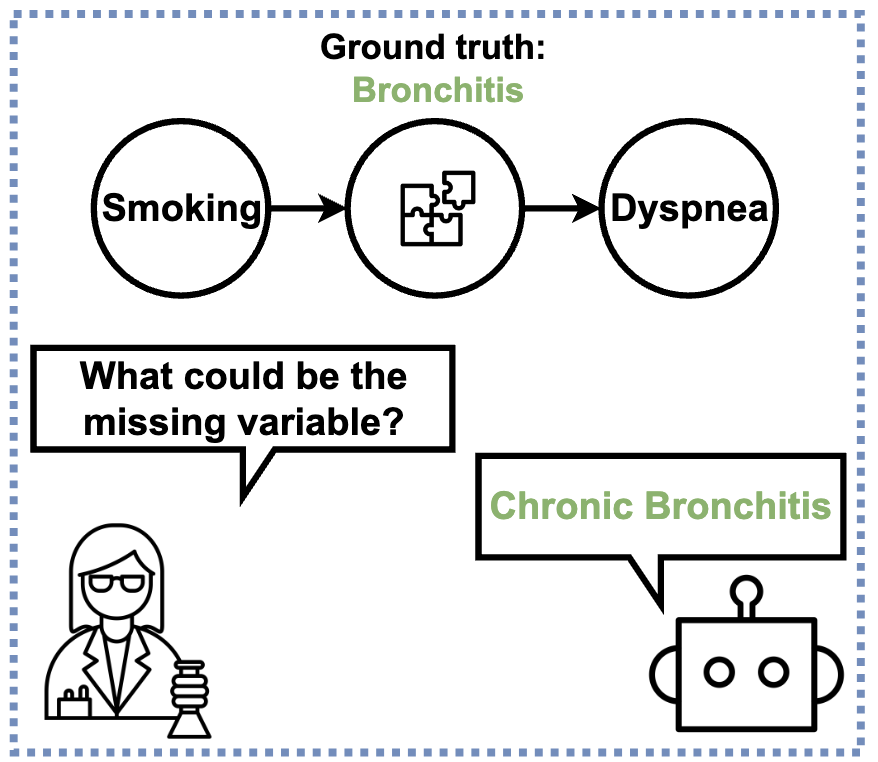
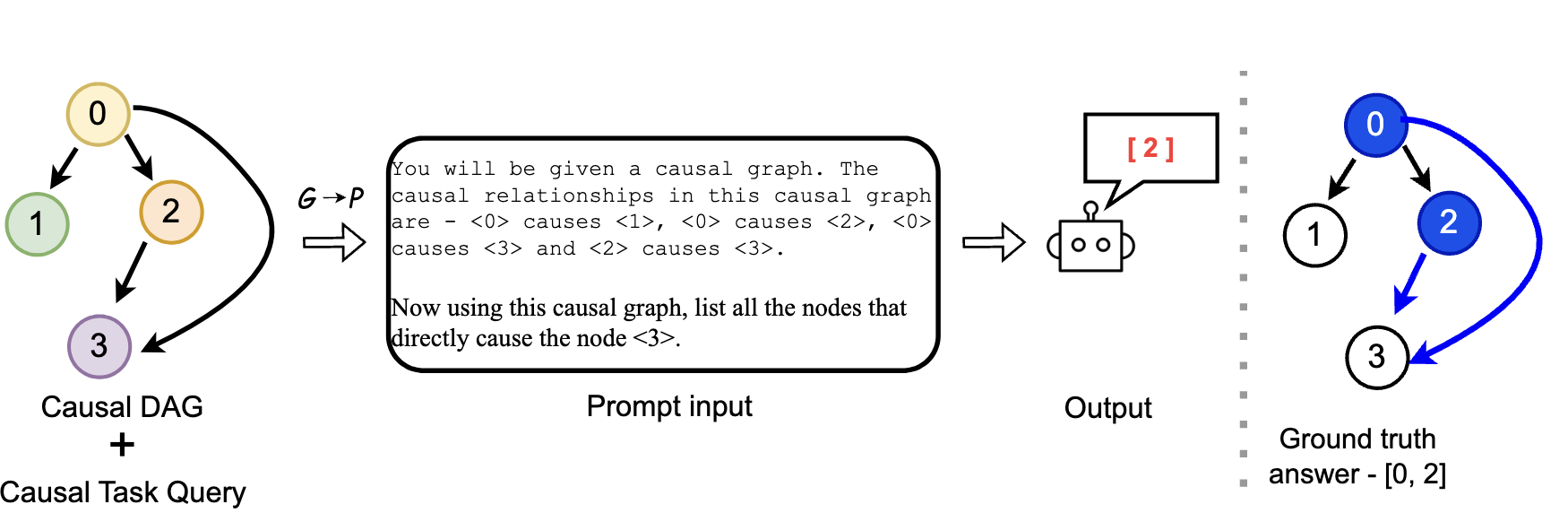
LLM framework for hypothesizing causal variables and building a causal graph from parametric knowledge and context.
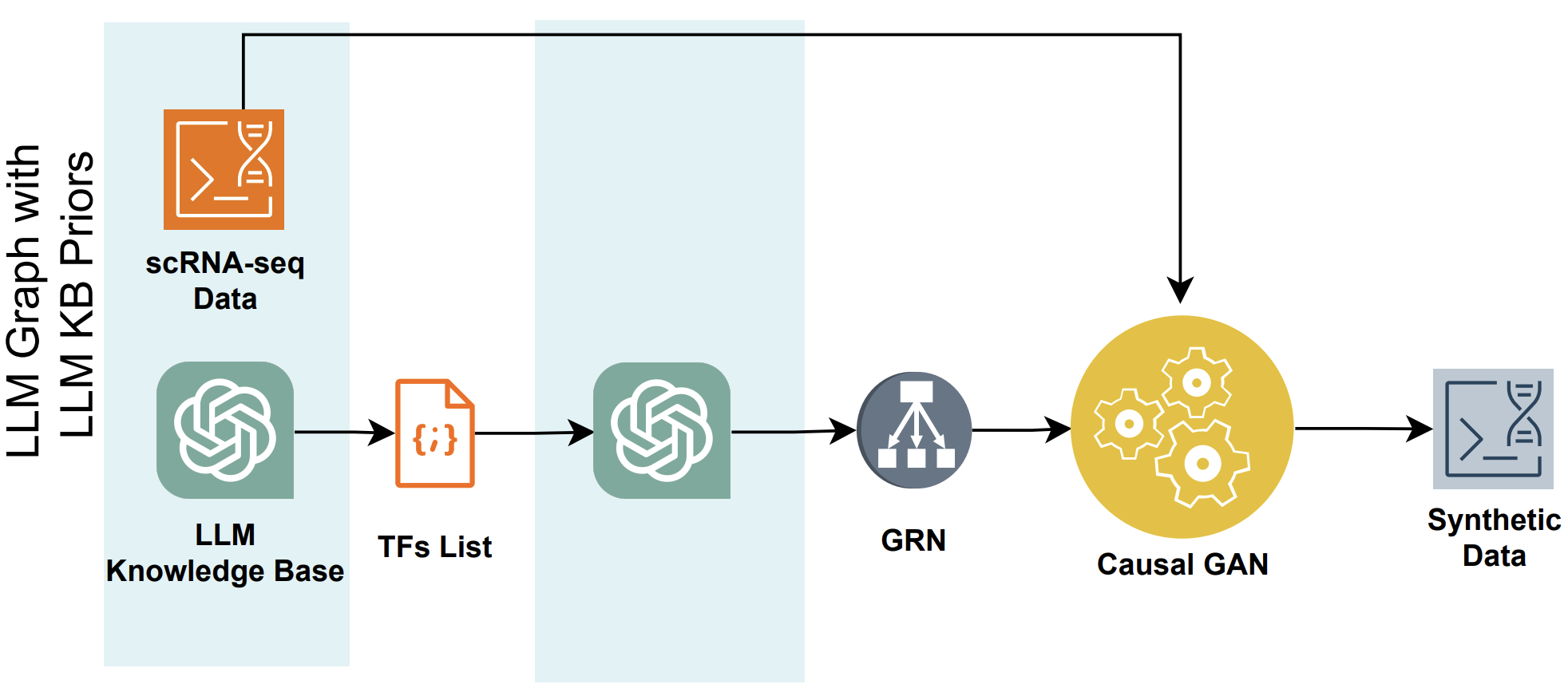
Explores LLM-assisted pipelines for inferring gene regulatory networks from RNA sequencing data.
Benchmark for evaluating LLMs' medical knowledge using graph-based probing tasks.
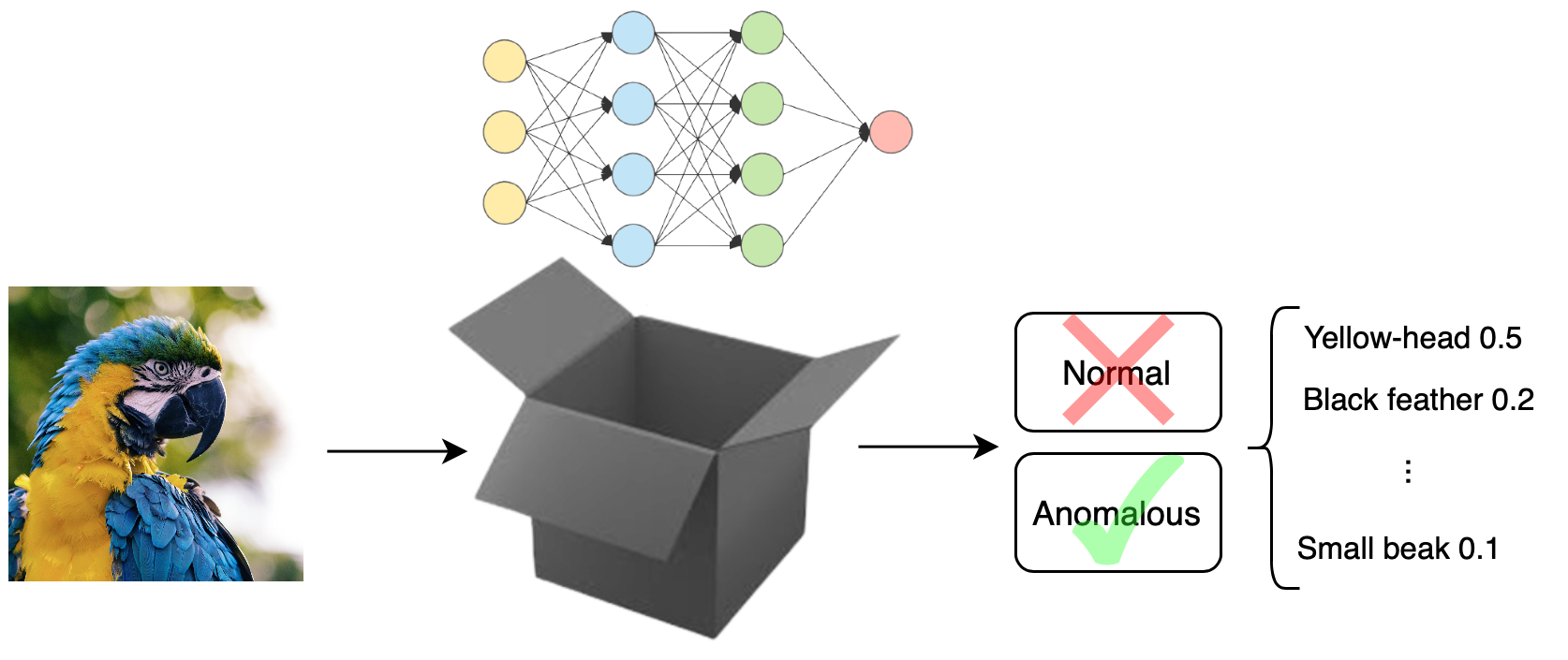
Introduces concept-based explanations for anomaly detection models.
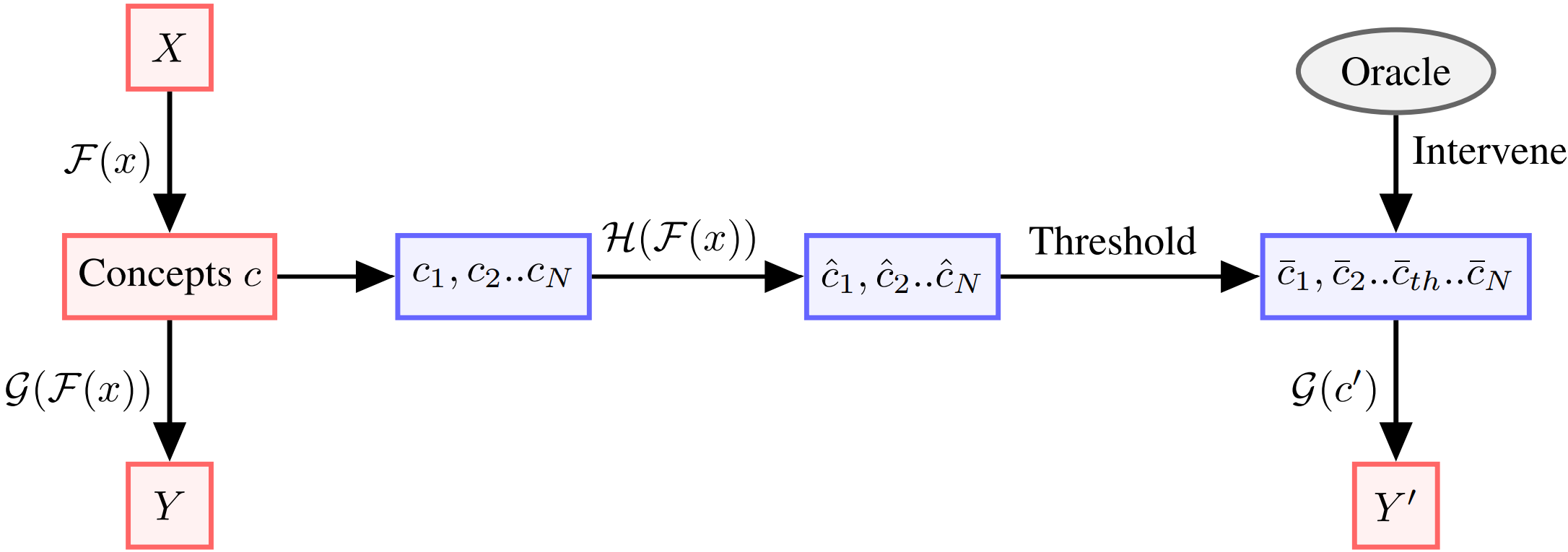
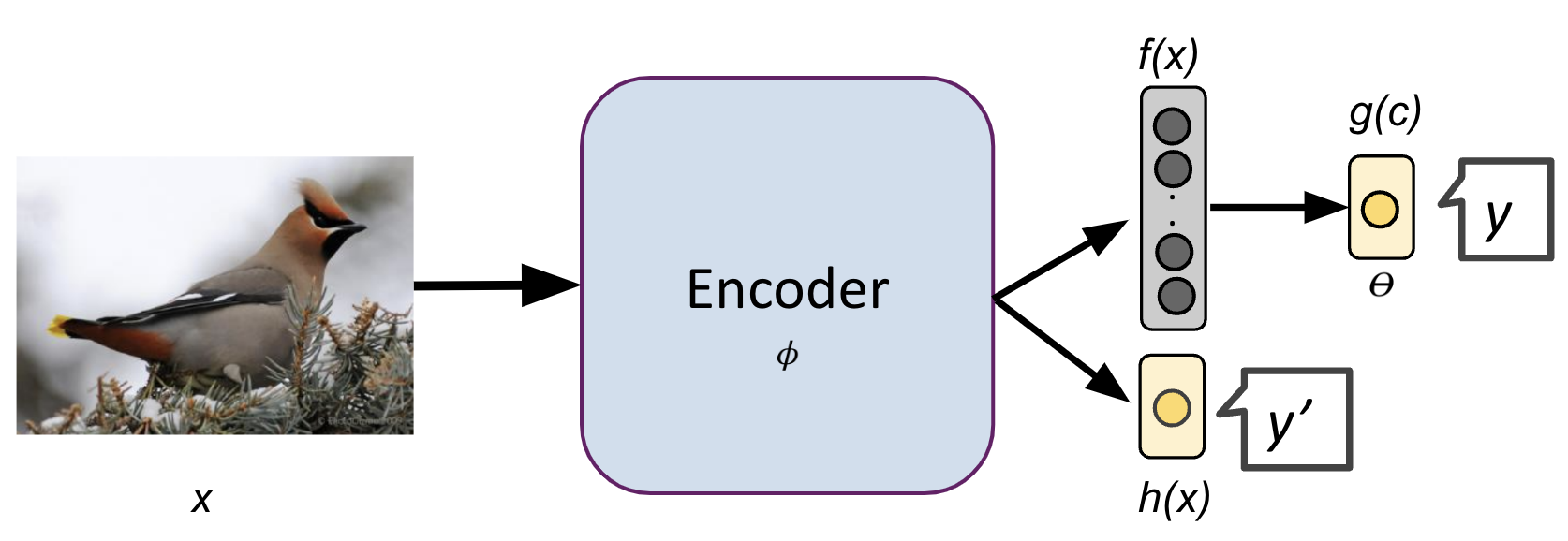
Proposes a framework for handling uncertain concepts in concept-based models using test-time interventions.
Realistic clinical benchmark for few-shot learning in histology.
Reviewer: ARR, NeurIPS, ICML, ICLR
Workshop Organizer: Women in Computer Vision at CVPR 2022 and CVPR 2023
I am a trained Kathak dancer (Indian classical dance), and I regularly teach and perform. In the summers, I enjoy container gardening. I also like to travel and cook veggie food 🍲. More recently, I have taken up punch-needle art 🌸.